
Single-Agent vs. Multi-Agent Systems
Should you use one agent or many?


You're building an agentic AI system. One of the first questions you'll face is deceptively simple: should you use one agent or many?
Here at Moltin, we've spent the last year implementing both approaches across hundreds of workflows. The answer isn't what most vendors will tell you. It's not about which architecture is "better." It's about matching the right pattern to your specific problem.
What We’re Really Talking About
A single-agent system uses one AI model to handle an entire workflow from start to finish. Think of it as hiring one very capable person to manage a project. They understand the full context, make all the decisions, and own the complete outcome.
Multi-agent systems split work across specialized agents. Each one handles a distinct piece of the puzzle. One agent might research information while another validates it and a third formats the output. They coordinate through structured handoffs or shared memory.
The difference isn't just architectural. It changes how you debug, how you scale, and how much you'll spend on tokens.
The Single-Agent Advantage
One agent means one context window. One set of instructions. One failure mode to debug. When something breaks at 2 AM, you’re not trying to figure out which agent in a chain of six dropped the ball.
I’ve watched teams spend weeks debugging multi-agent coordination issues that turned out to be simple prompt problems. With a single agent, you see the issue immediately. The model either understands the task or it doesn’t.
Deployment is faster too. You write one system prompt, test one set of behaviors, and push to production. No orchestration layer. No message queues. No distributed tracing to make sense of what happened.
Single agents maintain perfect context throughout a task. They remember what they learned in step one when they reach step five. There’s no lossy handoff between specialists who each see only part of the picture.
This matters more than you’d think. I’ve seen multi-agent systems hallucinate because Agent C never saw the constraint that Agent A discovered. The information got lost in translation between handoffs. A single agent can’t forget what it already knows.
The model can also adapt its strategy mid-execution. If the initial approach isn’t working, it pivots without needing to coordinate with three other agents. The flexibility is real.
Cost Efficiency for Straightforward Tasks
Here’s something vendors don’t advertise: multi-agent systems are expensive. Each agent generates tokens. Each handoff requires additional context-setting. You’re paying for coordination overhead on top of the actual work.
For tasks that don’t require true specialization, that overhead is waste. I’ve measured cases where multi-agent implementations cost 3-4x more in API calls than equivalent single-agent solutions. Same output, same quality, quadruple the bill.
If your workflow is linear and doesn’t branch much, one agent will almost always be cheaper. Save your budget for problems that actually need multiple perspectives.
When Single Agents Hit the Wall

Modern models have large context windows. Claude can handle ~200,000 tokens. Gemini can handle ~1,000,000 tokens. But just because you can stuff an entire workflow into one context doesn’t mean you should.
I’ve seen single agents lose the thread around the 50,000-token mark. They start forgetting instructions from the beginning. They repeat themselves. The quality degrades in ways that are hard to predict.
Complex workflows with lots of branching logic hit this wall fast. If your task has ten decision points and each one requires evaluating thousands of tokens of information, you’re asking one agent to juggle too much. The drops become inevitable.
Some tasks genuinely benefit from expertise. You wouldn’t ask a surgeon to also handle anesthesia and nursing. The same principle applies to agents.
A single agent trying to do everything becomes a generalist. It’s decent at research, okay at analysis, passable at formatting. But if you need expert-level SQL generation followed by expert-level data visualization, a generalist often falls short.
Single agents handling complex data pipelines make subtle mistakes that specialized agents catch. The SQL agent understands database-specific quirks. The visualization agent knows what makes charts readable. One agent trying to do both gets neither quite right.
When a single agent fails on step eight of a twelve-step process, you’ve got a mess. The error could be anywhere in the logic. The context is enormous. Good luck isolating the root cause.
You end up re-running the entire workflow repeatedly, tweaking prompts, hoping you’ve fixed it. Each test cycle burns time and money. There’s no easy way to unit-test just the part that’s broken.
Multi-agent systems let you isolate failures to specific agents. When the validation agent throws an error, you know exactly where to look. You can test that agent independently without running the full workflow.
The Multi-Agent Case
Breaking work into specialized agents forces clarity. Each agent has one job, and you can tune it specifically for that job. The research agent doesn’t need to know anything about formatting. The formatter doesn’t need research capabilities.
This separation makes prompts simpler. Instead of one massive system prompt trying to cover every scenario, each agent gets focused instructions. Less ambiguity means fewer edge-case failures.
It also makes the system easier to reason about. When you read the workflow diagram, you immediately understand what’s happening. Research feeds into validation, which feeds into formatting. The data flow is explicit.
Some workflows have natural parallelism. You need to check three different data sources simultaneously, or generate multiple variations of content to compare.
Multi-agent systems can run these operations concurrently. One agent hits the CRM while another queries the analytics platform and a third searches internal documentation. You get results in the time it takes the slowest agent to finish, not the sum of all three.
I’ve cut workflow execution time by 60-70% using parallel agents for tasks that don’t have strict dependencies. The speedup is real and it compounds as workflows grow.
Not every step needs your most powerful (and expensive) model. The agent that validates email addresses can run on a cheaper, faster model than the agent writing customer communications.
Multi-agent architectures let you optimize the cost-performance ratio for each piece. Use Opus for creative writing. Use Haiku for structured extraction. Use Sonnet for reasoning-heavy tasks.
This flexibility matters at scale. I’ve seen companies cut inference costs by 40% just by right-sizing models to tasks. The overall system gets faster too because simple agents finish quickly and don’t block the workflow.
When you need to improve the validation logic, you modify one agent. You test it in isolation. You deploy just that change. The rest of the system keeps running with zero risk.
This is dramatically different from modifying a monolithic agent. With single agents, every change touches the entire system. You’re never quite sure if you fixed the validation without breaking the research or formatting.
Multi-agent systems also support A/B testing. Run the old validation agent for 50% of requests and the new one for the other 50%. Compare results. Roll back instantly if the new agent underperforms.
The Hidden Costs of Multi-Agent Systems
Coordination Overhead
Agents don’t communicate telepathically. You need infrastructure to pass messages, share context, and synchronize state. This coordination layer is code you have to write, test, and maintain.
Every handoff between agents is a potential failure point. What happens if Agent B crashes after Agent A finishes? Do you retry? Do you start over? How do you ensure exactly-once processing?
I’ve seen teams spend more time building orchestration logic than actually implementing agent behaviors. The complexity creeps up on you. Suddenly you’re maintaining what’s essentially a distributed system with all the headaches that entails.
Debugging Distributed Failures
When a multi-agent workflow fails, tracing the issue requires following the execution path across agents. You need distributed logging, correlation IDs, and good observability. Otherwise you’re flying blind.
Even with great tooling, debugging is harder. The problem might be in Agent C, but it was caused by bad output from Agent A that Agent B didn’t catch. You’re doing root cause analysis across a chain of dependencies.
I’ve spent hours debugging issues that turned out to be prompt drift. Agent A changed its output format slightly, and Agent C couldn’t parse it anymore. Agent B in the middle passed it through without noticing. These cascading failures are subtle and time-consuming.
Prompt Drift and Version Management
You’ve got multiple agents, each with its own prompt. You update Agent B’s prompt to fix a bug. Now Agent B’s outputs have changed slightly, and Agent D downstream is confused.
Managing prompt versions across a system of agents is genuinely difficult. You need testing matrices that verify agent pairs still work together after updates. You need rollback plans. You need change logs.
Single agents don’t have this problem. There’s one prompt. You version it. Done.
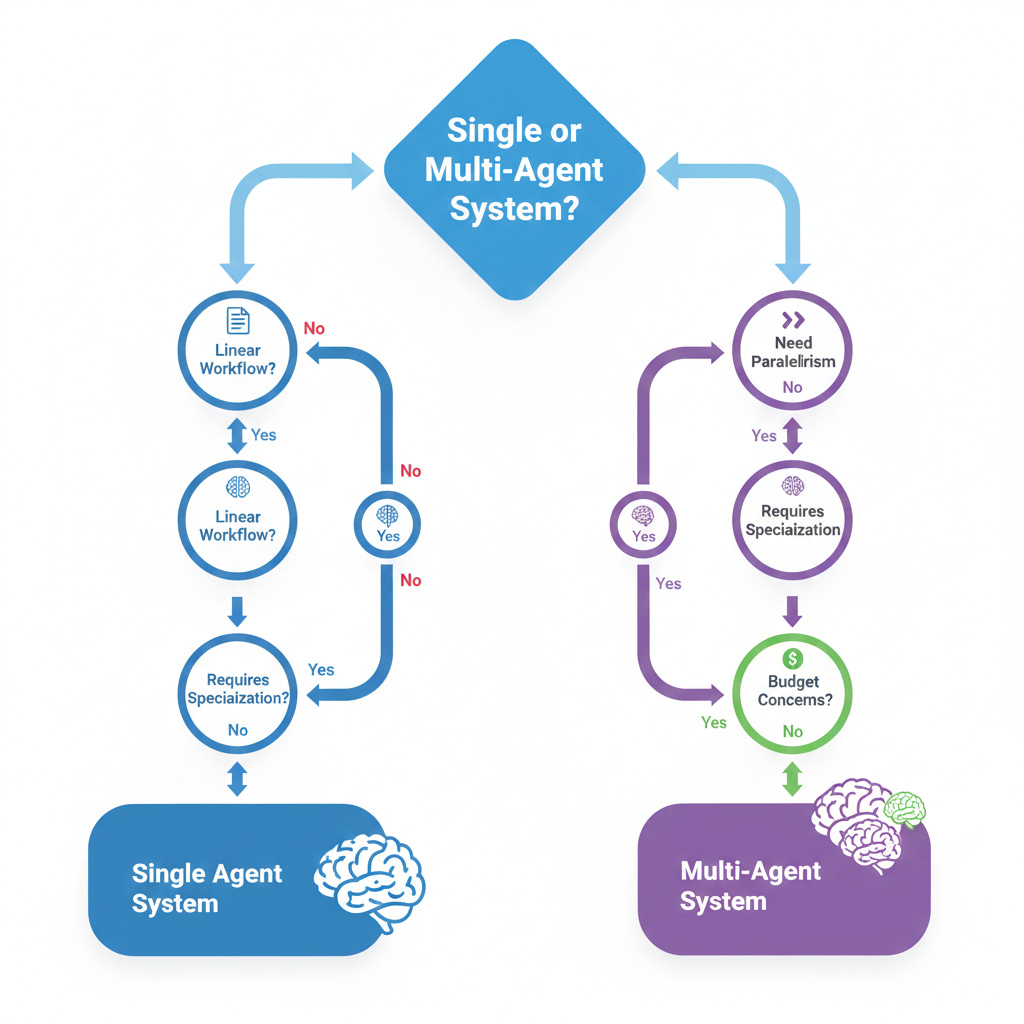
Making the Choice
Start with task complexity. Map out your workflow on paper. How many distinct steps are there? How much context does each step need from previous steps?
If the workflow is linear and each step builds directly on the last with heavy context requirements, lean toward a single agent. The task probably doesn’t need decomposition.
If you see clear breakpoints where one phase completes and hands off to a fundamentally different phase, that’s a signal for multi-agent. Research, then analysis, then formatting is a classic pattern that benefits from separation.
Consider your team’s capabilities. Multi-agent systems require stronger engineering. You need people who understand distributed systems, message passing, and state management. If your team is small or light on infrastructure experience, single-agent is safer.
You can always start simple and refactor later. I’ve seen too many teams over engineer from day one, building elaborate multi-agent frameworks before they’ve shipped a single workflow. Start with one agent. Prove the value. Then optimize.
Think about the maintenance burden. Who’s maintaining this system in six months? Multi-agent architectures create more surface area. More code. More potential breakage. More operational complexity.
If you’re building a one-off workflow, keep it simple. If you’re building a platform that’ll run thousands of workflows, the investment in proper multi-agent infrastructure might pay off. Scale matters.
Test both when possible. The best answer comes from empirical data. Build a prototype with a single agent. Build another with multiple agents. Run them both on real tasks and measure what actually matters: accuracy, latency, cost, and maintenance burden.
I’ve been surprised more than once. Tasks I thought needed multi-agent worked fine with one. Tasks that seemed simple benefited from specialization. Your intuition will be wrong sometimes.
Hybrid Approaches
You don’t have to choose just one pattern. Some workflows use a single agent for most of the work and spawn specialized agents for specific subtasks.
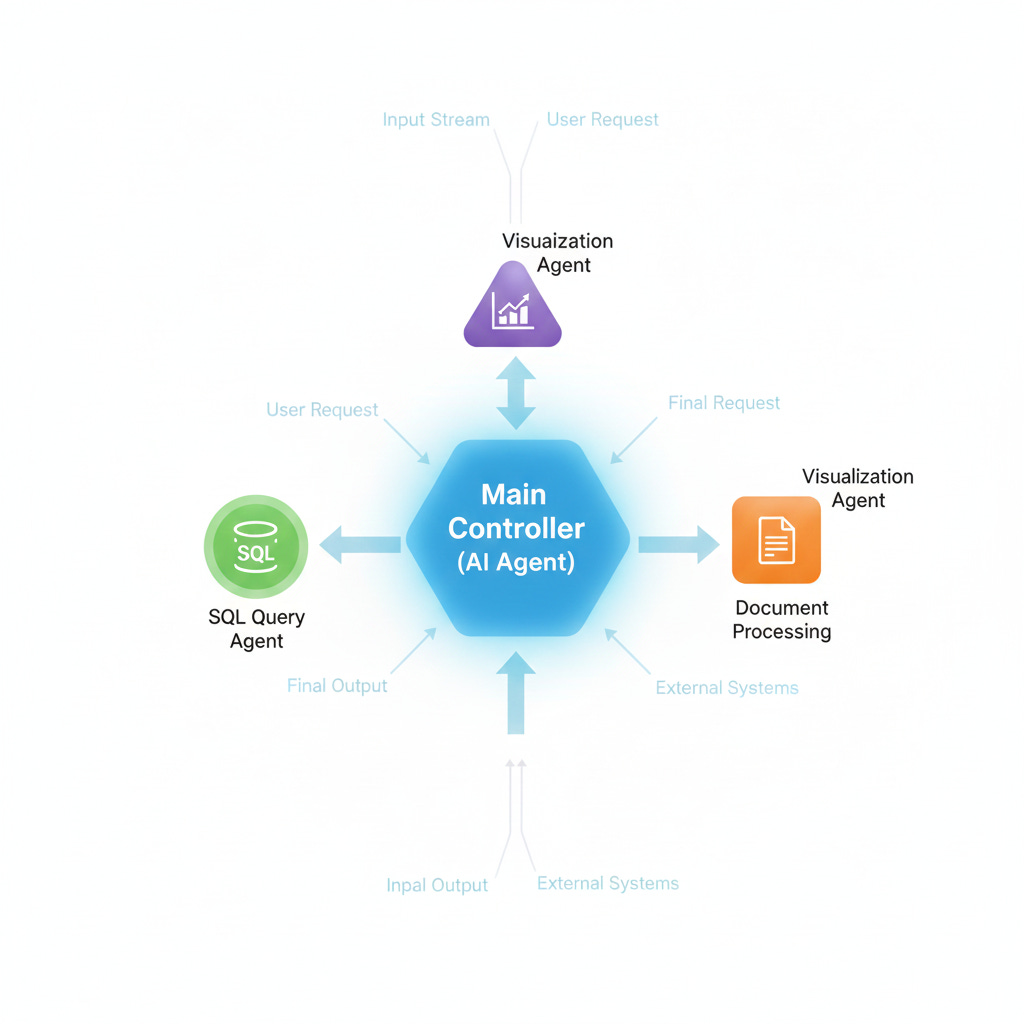
For example, your main agent handles the workflow logic but calls out to a specialized SQL agent when it needs to generate queries. The SQL agent is isolated, testable, and optimized. But you’re not managing a full multi-agent orchestration system.
This middle ground often makes sense. You get specialization where it matters without the overhead of coordinating everything through message passing. The main agent stays in control and maintains context.
I’ve used this pattern for workflows that are mostly straightforward but have one or two steps that need deep expertise. It’s the best of both worlds when it fits.
What the Research Shows
Academic papers love multi-agent systems. They’re fascinating to study and produce impressive demos. But research metrics don’t always transfer to production.
Many papers test on toy problems or benchmarks that favor coordination. They measure agent collaboration in controlled environments. Real workflows are messier. They have edge cases, noisy inputs, and strict latency requirements.
The research also rarely accounts for operational costs. A system that scores 2% better on accuracy but costs 4x more and takes twice as long to debug isn’t obviously better. Context matters.
That said, the research does validate some patterns. Specialized agents consistently outperform generalists on complex reasoning tasks. Parallel execution really does speed things up. The findings are directionally correct even if the magnitude is overstated.
The Evolution Path
Most successful agentic systems start simple and grow in complexity. You begin with a single agent handling a narrow workflow. You ship it. You learn what breaks.
Then you identify the bottleneck. Maybe it’s the research phase that’s slow. Maybe the formatting is error-prone. You extract that piece into a specialized agent. You test it. You measure the impact.
Over time, you end up with a hybrid system that’s grown organically based on real needs. This beats starting with a grand multi-agent architecture that turns out to be overbuilt for the actual problem.
I’ve never seen a team regret starting simple. I’ve seen plenty regret starting complex.
Lessons from the Field
After shipping dozens of agentic workflows, here’s what I’ve learned matters most:
Single agents shine when context coherence is critical and the task is straightforward. Use them for workflows where losing the thread would be catastrophic. Use them when you need fast iteration and simple debugging.
Multi-agent systems win when specialization improves quality or parallelism cuts latency. Use them when different steps genuinely need different expertise. Use them when you can afford the coordination overhead.
The decision isn’t permanent. You can refactor. But you’ll ship faster and learn more by starting with the simplest thing that could work.
Most teams overcomplicate. They read about sophisticated multi-agent frameworks and assume they need that level of sophistication. They don’t. Not yet anyway.
Build one agent that solves a real problem. Ship it to users. Collect feedback. Then decide if you need more agents. Let the actual requirements drive the architecture, not the other way around.
That’s how you build agentic systems that actually work.